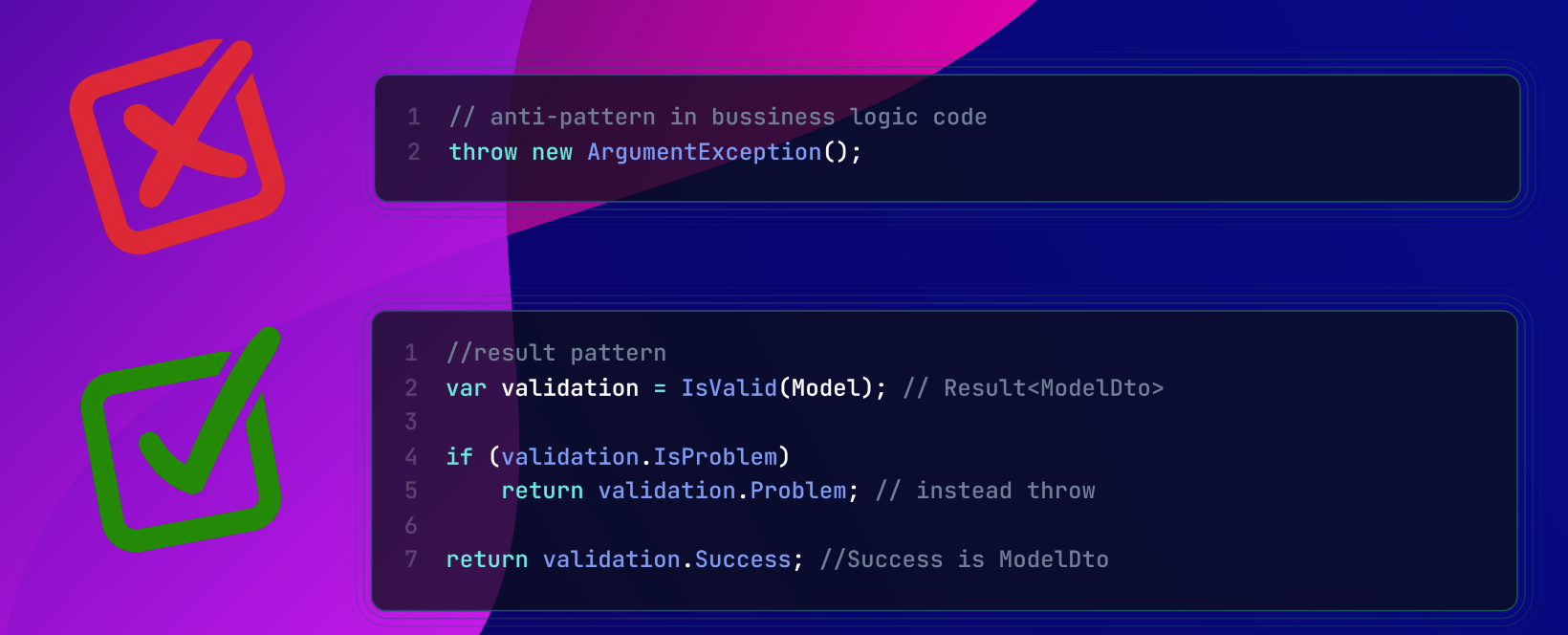
This article gathers best practices and insights from various implementations of the result pattern—spanning multiple languages and frameworks—to help you integrate these ideas seamlessly into your .NET applications.
Crafting a Result Pattern in C#: A Comprehensive Guide
This article gathers best practices and insights from various implementations of the result pattern—spanning multiple languages and frameworks—to help you integrate these ideas seamlessly into your
Introduction to Result Pattern vs. Exception-Based Flow
Traditionally, C# applications have relied on exceptions for error handling. While exceptions are invaluable for truly unexpected issues, they can be overused for expected or recoverable failures, leading to several issues:
Performance Improvements:
Throwing and catching exceptions is inherently expensive. The result pattern avoids this overhead by returning a structured value, which is especially beneficial in high-volume applications.
Simplified Code Flow:
With the result pattern, success and failure cases are explicitly represented. Developers don’t need to sift through try/catch blocks—the control flow is clearly delineated.
Maintainability:
Centralizing error handling in a result type makes your code easier to maintain. When error logic is encapsulated within a well-defined type, debugging and testing become less complex.
Clarity in Intent:
When a function returns a result, it’s immediately clear to the consumer that the operation may fail. This explicit contract improves code readability and encourages handling both outcomes.
The Cultural Relevance of the Result Pattern
Every good programmer has likely reinvented the result pattern at least once in their life to control flow, and even languages like Go have embedded it as a core feature. This idea isn’t unique to .NET - it’s a recurring theme throughout programming history.
Back in the day, C programmers would often return error codes from functions (say hello to the application exit codes), leaving it to the caller to inspect and handle each outcome. It wasn’t elegant, but it was a solution born of necessity. As programming languages evolved, exceptions emerged in languages like C++ and Java. They promised a cleaner way to handle errors by separating normal logic from error logic. Yet, as many of us have discovered, exceptions can be heavy, unpredictable, and hard to manage in high-performance or highly scalable systems. Microsoft itself strongly recommends against using exception-based control flow: First, Second, Third and even Fourth mention.
About the result pattern. Functional languages like Haskell embraced a similar concept with the “Either” type, a tool designed to express success or failure in a single, unified return value. This idea found fertile ground in languages like F#, where a built-in Result type made error handling both explicit and type-safe. Fast forward to modern times, and Rust has taken the concept to a new level with its own Result type, ensuring that error handling is not an afterthought but a core part of the function’s contract.
Even in the dynamic world of JavaScript and later in TypeScript (child of MS), developers have created patterns and libraries that mimic this approach, favoring explicit control flow over hidden exception paths. What’s fascinating is that while the syntax and language paradigms have changed over the decades, the core challenge of cleanly and predictably handling errors remains the same.
Comparing Existing Libraries in the .NET Ecosystem
The main point of this article is to help implement own Result/Exception/Error that fits your project needs, but first of all let’s compare what community can offer.
Several libraries implement variations of the result pattern, each with its own strengths and trade-offs:
Benefits | Limits | |
Provides a clean way to create discriminated unions in C#. It integrates well with pattern matching and allows you to return one of multiple types. | It may require additional boilerplate or careful handling when converting between types. We are going to use this library as a base for our result pattern. | |
Offers a rich set of functional constructs, including Result, Value Objects, and even support for lazy evaluation. | This library might be better suited for projects where you want a full suite of functional programming tools alongside the result pattern. | |
Similar to OneOf, Either provides a way to encapsulate success or failure without exceptions. | Use this when you want a simpler, more lightweight implementation. |
Each library has its merits. Choosing one depends on your project’s complexity, the team’s familiarity with functional patterns, and specific requirements regarding type safety and boilerplate reduction.
Step-by-Step Implementation of a Custom Result Pattern
Basic Setup and Structure
Start by defining a result type that encapsulates both success and error cases. This is a core of our pattern, that will be used across all project. I strongly recommend to move this code to separate .csproj for easier dependency management.
Defining the Interfaces and Result Types
/// <summary>
/// In C#, pattern matching against generic types requires a known type argument at compile time.
/// Since IResultPattern(T) is generic and the type parameter T is unknown, direct pattern matching is not possible.
/// To overcome this, a non-generic base interface (IResultPattern) provides a common contract,
/// enabling type-agnostic operations without resorting to reflection, which can impact performance and maintainability.
/// see <see cref="ResultActionFilter"/>
/// </summary>
public interface IResultPattern
{
bool IsSuccess { get; }
bool IsProblem { get; }
object Success { get; }
Problem Problem { get; }
}
public interface IResultPattern<out T> : IResultPattern
{
new T Success { get; }
}
[GenerateOneOf]
public partial class Result<T> : OneOfBase<T, Problem>, IResultPattern<T> where T : class
{
public bool IsSuccess => IsT0;
public bool IsProblem => IsT1;
public T Success => AsT0;
public Problem Problem => AsT1;
// Explicit implementation for non-generic interface
object IResultPattern.Success => Success;
}
[GenerateOneOf]
public partial class VoidResult : OneOfBase<bool, Problem>, IResultPattern<bool>
{
public bool IsSuccess => IsT0 && AsT0;
public bool IsProblem => IsT1;
public bool Success => AsT0;
public Problem Problem => AsT1;
// Explicit implementation for non-generic interface
object IResultPattern.Success => Success;
}Defining the Error (Problem) Type
public class Problem
{
[JsonIgnore]
public HttpStatusCode StatusCode { get; init; }
[JsonPropertyName("Description")]
public string? Description { get; init; }
[JsonPropertyName("ErrorCode")]
public ErrorCode ErrorCode { get; init; }
[JsonPropertyName("Errors")]
public List<BusinessLogicCase> Errors { get; set; } = new();
public override string ToString()
{
return JsonSerializer.Serialize(this);
}
}The design starts with the IResultPattern interfaces.
The non-generic IResultPattern defines a simple contract. It tells if an operation succeeded or failed and exposes either a success value or error details. The generic IResultPattern
Next is the Result
It provides clear properties to check if the result is a success or a problem. The [GenerateOneOf] attribute cuts down on boilerplate by generating necessary conversion methods. This class is the backbone of the result pattern.
VoidResult follows a similar approach.
It is used when no data needs to be returned. It wraps a boolean value and a Problem. A true boolean indicates a successful operation. It standardizes how void operations are handled in this pattern.
On the other hand the Problem class encapsulates error information.
It holds a status code, a description, an error code, and a list of detailed errors. It replaces the need for exceptions by providing a structured error response. Its JSON serialization helps with logging and API responses. We intend to return this object as the result of the API in case of an error.
Together, these components create a system that clearly separates success from failure. They provide a consistent way to handle outcomes throughout the application.
At this point you are ready to go, implementation are ready to use. But I continue to add some features that are especially developed to be used in ASP.NET Core, such as OpenAPI specification generation and proper handling of direct return of the Result object from the API route.
But first, let’s dig down what benefits do we have with OneOf library
Integrating the OneOf Library
By leveraging the OneOf library, we create a discriminated union that cleanly represents either a success (with a value) or a problem (with error details). This design simplifies the handling of multiple possible states and keeps your domain logic clean.
The GenerateOneOf attribute is a real game-changer. It automatically creates conversion methods that let you work with your result type almost as if it were a union of two unrelated types. Behind the scenes, it generates a constructor that wraps a union containing either a success value or an error. This means you can build a Result
Generated code that allow us to do “magic” with types:
partial class Result<T>
{
public Result(OneOf.OneOf<T, global::AppraiSys.Essential.ResultPattern.ResultPattern.Problem> _) : base(_) { }
public static implicit operator Result<T>(T _) => new Result<T>(_);
public static explicit operator T(Result<T> _) => _.AsT0;
public static implicit operator Result<T>(global::AppraiSys.Essential.ResultPattern.ResultPattern.Problem _) => new Result<T>(_);
public static explicit operator global::AppraiSys.Essential.ResultPattern.ResultPattern.Problem(Result<T> _) => _.AsT1;
}For example, notice the implicit conversion from T to Result
Imagine you have a method that can either produce a valid model or an error. With the generated conversions, your method looks clean:
public async Task<Result<ModelDto>> DoSomething()
{
if (/* some error condition */)
return new Problem { /* error details */ };
return new ModelDto { /* model data */ };
}Here, you don’t need to wrap ModelDto or Problem in a special base class. The generated methods handle that. You can return either type directly. This provides you with powerful flexibility. It means your API can express multiple outcomes in a natural way. The code remains concise, and the intent stays clear.
In short, the GenerateOneOf attribute drills down to the core of result handling. It removes boilerplate code and lets you focus on the business logic. With these conversion operators in place, your methods can effortlessly return different types while maintaining type safety and clarity.
Result object and API
Now you may ask a question, what if we directly return a Result object from API route? What outcome will we have?
Well, we need to think about it and create such integration to generate clear OpenAPI specification without mention of the Result and a proper handling for cases when our Result is not success at all but Problem returned by underlying logic.
Let’s start with simpler and update OpenAPI spec generation for all routes that returns Result, to make this happen let’s create OpenApiResultOperationFilter.
The OpenApiResultOperationFilter is our bridge to clear and accurate API documentation. Imagine you have an API method that returns our custom Result type. Without this filter, Swagger or other OpenAPI tools might simply see an ambiguous object. They wouldn’t know if your method returns a ModelDto on success or a Problem on error. The generated docs would be vague, leaving consumers uncertain about the actual data structure.
With the filter in place, the logic drills down into the method’s return type. It starts by unwrapping any Task<> (I hope that all your routes are async, if not Houston we have a problem) wrappers to reveal the underlying type. Then it checks if this type implements IResultPattern. This is where our non-generic IResultPattern interface comes into play. It allows a type-agnostic check so that regardless of the specific success type , the filter recognizes the pattern.
Once confirmed, the filter clears the default responses and builds a clear specification. It generates a schema based on the success type if there is one. For instance, if your method returns a Result, the filter uses reflection to generate a schema for ModelDto. It also sets up distinct responses for different HTTP status codes. A 200 response might indicate success with a ModelDto payload, while responses like 400 or 401 point to a Problem schema. Even a 500 response is handled, providing a schema for ProblemDetails.
public class OpenApiResultOperationFilter : IOperationFilter
{
public void Apply(OpenApiOperation operation, OperationFilterContext context)
{
// Get the return type of the method (e.g., Task<Result<,>>)
var returnType = context.MethodInfo.ReturnType;
// Unwrap Task<>
if (returnType.IsGenericType && returnType.GetGenericTypeDefinition() == typeof(Task<>))
{
returnType = returnType.GetGenericArguments()[0];
}
// Check if returnType implements IResultPattern
if (!typeof(IResultPattern).IsAssignableFrom(returnType))
{
return;
}
var genericArgument = returnType.GetGenericArguments().FirstOrDefault();
operation.Responses.Clear();
var isVoidResult = genericArgument == null;
var schema = isVoidResult ? null : context.SchemaGenerator.GenerateSchema(genericArgument, context.SchemaRepository);
var isGenericIList = genericArgument?.GetInterfaces()
.Any(i => i.IsGenericType && i.GetGenericTypeDefinition() == typeof(IList<>)) ?? false;
operation.Responses["200"] = new OpenApiResponse
{
Description = isVoidResult ? "Ok" : isGenericIList ? $"Ok, array of {genericArgument!.GetGenericArguments()[0].Name}" : $"Ok, {genericArgument!.Name}",
Content = new Dictionary<string, OpenApiMediaType>
{
["application/json"] = new()
{
Schema = schema,
},
},
};
operation.Responses["204"] = new OpenApiResponse
{
Description = "No content",
};
var notSuccessResultSchema = context.SchemaGenerator.GenerateSchema(typeof(Problem), context.SchemaRepository);
operation.Responses["400"] = new OpenApiResponse
{
Description = "Bad request, validation error",
Content = new Dictionary<string, OpenApiMediaType>
{
["application/json"] = new()
{
Schema = notSuccessResultSchema,
},
},
};
operation.Responses["401"] = new OpenApiResponse
{
Description = "Not Authorized",
Content = new Dictionary<string, OpenApiMediaType>
{
["application/json"] = new()
{
Schema = notSuccessResultSchema,
},
},
};
var internalServerErrorSchema = context.SchemaGenerator.GenerateSchema(typeof(ProblemDetails), context.SchemaRepository);
operation.Responses["500"] = new OpenApiResponse
{
Description = "Server side error",
Content = new Dictionary<string, OpenApiMediaType>
{
["application/json"] = new()
{
Schema = internalServerErrorSchema,
},
},
};
}
}This logic ensures that every potential outcome of your API method is documented. If you return a Problem, clients see a well-defined error structure. If you return a successful result, they know exactly what to expect. Without this filter, your API documentation would lack this level of detail. Consumers might have to guess or read through code, instead of relying on an automatically generated, clear contract.
In essence, the OpenApiResultOperationFilter elevates your API documentation. It translates our custom result pattern into a format that tools like Swagger can display, ensuring that both success and error responses are accurately represented. This makes your API more transparent and easier to integrate with, benefiting both developers and end users.
So, for code like:
[HttpGet]
[Permission(ResourceConstant.User, ActionsConstant.Read)]
public async Task<Result<List<UserClientViewModel>>> GetClientsList()
{
return await _userService.GetClientList(); // note, this method directly return Result<List<UserClientViewModel>>
}Swagger spec will look like:
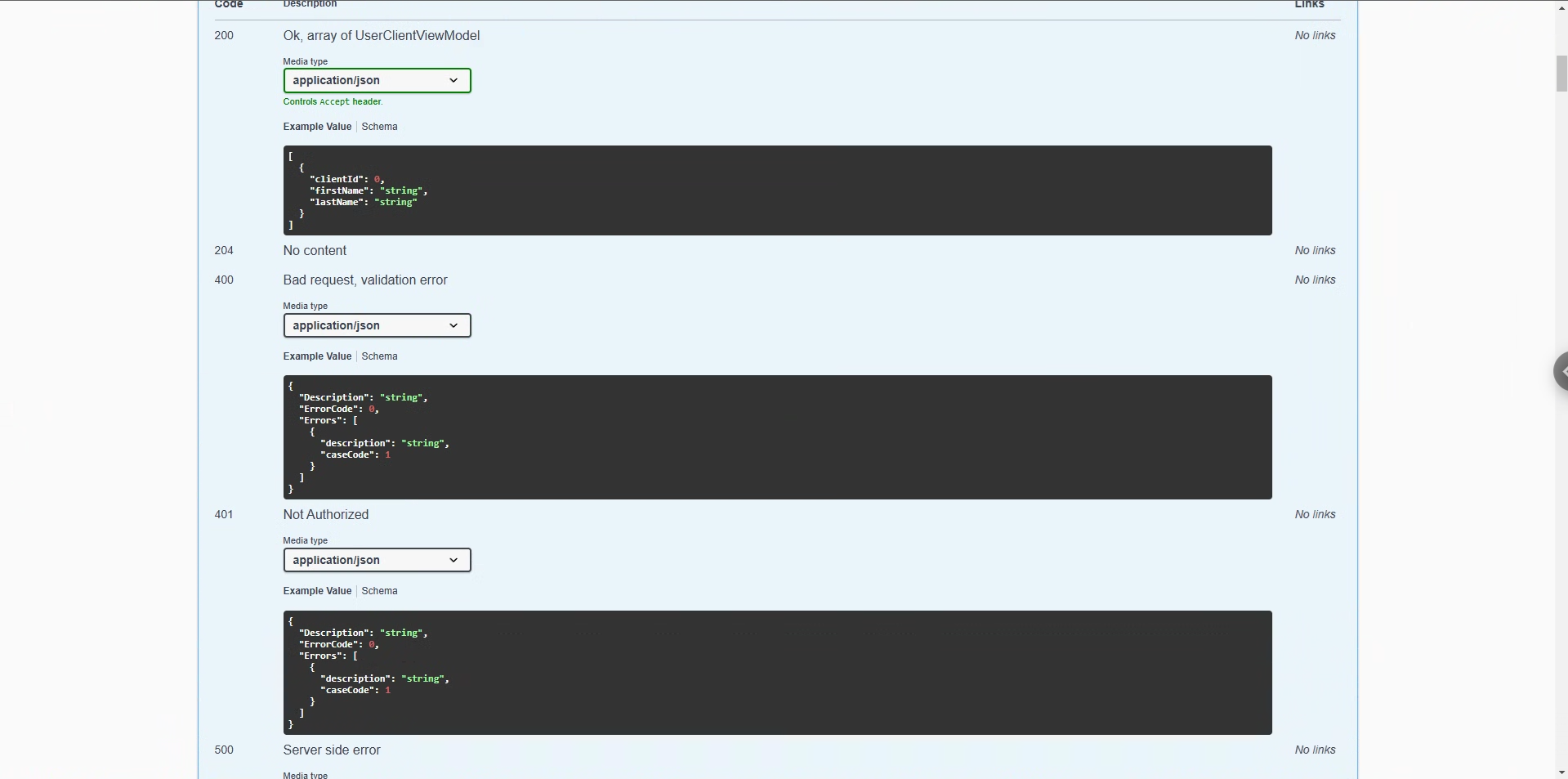
Proper generated body for all possible return types
Unified API Response Handling with ResultActionFilter
The ResultActionFilter is our way of centralizing response transformation. It intercepts every action result and checks if it implements the IResultPattern interface. Thanks to this, we don’t have to clutter our controller actions with repetitive if-checks and manual response creation. When an action returns a result, the filter first waits for the action to complete. It then examines the result. If the result is an object that follows our custom pattern, the filter inspects whether it represents success or a problem.
If the result signals success, the filter checks further. In cases where the success value is a boolean, it translates a true value into an HTTP 200 OK response and a false into a 400 Bad Request. Otherwise, it wraps the success value in an HTTP 200 OK response. In the event of a problem, the filter extracts the error details and creates a response using the provided HTTP status code from the error object.
public class ResultActionFilter : IAsyncActionFilter
{
public async Task OnActionExecutionAsync(ActionExecutingContext context, ActionExecutionDelegate next)
{
var resultContext = await next();
if (resultContext.Result is ObjectResult { Value: IResultPattern resultPatternValue })
{
if (resultPatternValue.IsSuccess)
if (resultPatternValue.Success is bool voidResult)
resultContext.Result = voidResult ? new OkResult() : new BadRequestResult();
else
resultContext.Result = new OkObjectResult(resultPatternValue.Success);
else
{
var errorResult = resultPatternValue.Problem;
resultContext.Result = new ObjectResult(errorResult)
{
StatusCode = (int)errorResult!.StatusCode,
};
}
}
}
}
public class ResultActionFilterProvider : IFilterProvider
{
public void OnProvidersExecuting(FilterProviderContext context)
{
var filter = new ResultActionFilter();
var filterItem = new FilterItem(new FilterDescriptor(filter, FilterScope.Action))
{
Filter = filter,
IsReusable = false,
};
context.Results.Add(filterItem);
}
public void OnProvidersExecuted(FilterProviderContext context) { }
public int Order => -1000;
}Note: this filter intended to be used as a GlobalFilter i.e. on all routes.
Without this filter, each controller action would need to handle this branching logic individually. That would lead to duplicate code scattered throughout the project and increased chances of inconsistencies. The filter makes the process seamless. The ResultActionFilterProvider ensures that this filter is automatically registered. It attaches the filter to every action without the developer needing to manually add attributes to each controller.
In short, the ResultActionFilter simplifies our API responses. It guarantees that the custom result pattern is consistently transformed into appropriate HTTP responses. This not only cleans up our code but also improves the overall maintainability of the application.
Comparing Result Pattern to Exception Flow
When you compare the result pattern to the traditional exception approach, the difference becomes clear in how the flow is controlled. Imagine a method that fetches a user by ID. With the result pattern, the method simply returns a result that holds either the user or a problem. There’s no need for try/catch blocks. The code directly checks if the user exists and returns the appropriate result. For example:
public Result<User> GetUserById(int id)
{
var user = repository.FindUser(id);
if (user is null)
return new Problem { StatusCode = HttpStatusCode.NotFound, Description = "User not found" };
return user;
}In a traditional exception-based flow, the same method throws an exception when the user isn’t found. This interrupts the normal flow and requires handling the exception somewhere up the call chain:
public User GetUserById(int id)
{
var user = repository.FindUser(id);
if (user is null)
throw new NotFoundException("User not found");
return user;
}The result pattern keeps the code flow linear and clear. The consumer of the method just examines the result instead of dealing with an exception.
Now consider a scenario where an operation might have multiple outcomes, such as processing a payment. With the result pattern, you can handle different cases—like validation errors, warnings, or success—by returning a structured result:
public Result<Payment> ProcessPayment(PaymentRequest request)
{
if (!Validate(request))
return new Problem { StatusCode = HttpStatusCode.BadRequest, Description = "Validation error" };
var payment = paymentService.Process(request);
if (payment.IsProblem)
{
logger.LogWarning("payment processing went wrong {Problem}", payment.Problem);
return new WarningPayment(payment, "Payment processed with warnings"); // you can derive from Problem type if you want to
}
return payment; //or payment.Success
}Contrast this with the traditional approach where you use try/catch blocks and throw different exceptions for each outcome:
public Payment ProcessPayment(PaymentRequest request)
{
try
{
if (!Validate(request))
throw new ValidationException("Validation error");
var payment = paymentService.Process(request);
if (payment.IsWarning)
throw new PaymentWarningException("Payment processed with warnings");
return payment;
}
catch (Exception ex)
{
// Handle or log exception
throw;
}
}Using the result pattern creates a more predictable and clean flow. There’s no scattering of try/catch blocks throughout the code. Instead, each method clearly communicates its possible outcomes by returning a well-defined result. Consumers can then simply check if the operation was successful or if there was a problem, without digging through exception handling logic. This leads to code that is easier to maintain and test, and overall makes the developer’s life a bit simpler.
Benchmarking the Result Pattern
Using BenchmarkDotNet, the following code demonstrates the performance benefits of the result pattern compared to exception throwing:
[MemoryDiagnoser]
public class ResultPatternBenchmark
{
private const int Iterations = 100_000;
private Result<string> GetResultPatternResult()
{
if (new Random().Next(0, 2) == 0)
return "Success";
return new Problem();
}
private int ThrowException()
{
if (new Random().Next(0, 2) == 0)
return 42;
throw new InvalidOperationException("An error occurred");
}
[Benchmark]
public void BenchmarkResultPattern()
{
for (int i = 0; i < Iterations; i++)
{
var result = GetResultPatternResult();
// Optionally, do something with the result
}
}
[Benchmark]
public void BenchmarkExceptionThrowing()
{
for (int i = 0; i < Iterations; i++)
{
try
{
var value = ThrowException();
// Optionally, do something with the value
}
catch (Exception)
{
// Optionally, handle the exception
}
}
}
}
internal class Program
{
static void Main(string[] args)
{
BenchmarkRunner.Run<ResultPatternBenchmark>();
}
}Benchmark Results:
BenchmarkDotNet v0.14.0, Windows 10 (10.0.19045.5487/22H2/2022Update)
11th Gen Intel Core i7-11700K 3.60GHz, 1 CPU, 16 logical and 8 physical cores
.NET SDK 9.0.101
[Host] : .NET 8.0.11 (8.0.1124.51707), X64 RyuJIT AVX-512F+CD+BW+DQ+VL+VBMI [AttachedDebugger]
DefaultJob : .NET 8.0.11 (8.0.1124.51707), X64 RyuJIT AVX-512F+CD+BW+DQ+VL+VBMI
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|--------------------------- |-----------:|----------:|----------:|----------:|----------:|
| BenchmarkResultPattern | 9.241 ms | 0.1739 ms | 0.4132 ms | 1765.6250 | 14.12 MB |
| BenchmarkExceptionThrowing | 185.322 ms | 1.6657 ms | 1.3910 ms | 2000.0000 | 17.55 MB |The result pattern method completes in just a few milliseconds and uses significantly less memory, while the exception method takes over 185 milliseconds with much higher memory allocation. This benchmark drives home the point that by avoiding exceptions for routine control flow, we can achieve much better performance, especially in high-volume scenarios.
Conclusion
In conclusion, adopting the result pattern transforms how our applications handle outcomes. It streamlines the code by making both success and error cases explicit, thereby eliminating the clutter of try/catch blocks. This clarity makes the code easier to maintain and test. Moreover, the centralized error management that the result pattern offers means that error handling is consistent across the application. As we have seen, the performance benefits are significant, reducing both execution time and memory overhead. In essence, the result pattern not only improves performance but also enhances the overall development experience, I believe it must be an essential tool in every programmer’s toolkit.